Maintaining control of our data with personal databases
Relational databases are in their sixth decade, and the database community is understandably celebrating and reflecting on its accomplishments. In two wonderful pieces, Donald Chamberlin shared his perspective on the past half-century, and Eugene Wu shared thoughts on where we can go from here. At a time of reflection on relational database management systems as a largely solved problem, I’m struck by a painful contrast: databases are more powerful than they’ve ever been, but the average person’s relationship with their data is in the worst state it’s ever been.
The fundamental problem is that in using most modern consumer-oriented applications, we lose control of the data we share with those applications. In creating documents, writing emails, or tracking our exercise or other activities, we share data with an application that’s useful for a particular purpose, but also allow the data live in a database controlled by the application’s owner. With the data outside of our control, it can then be restricted, lost, leaked, sold, resold, and exploited. The groups that control these databases accrue most of the benefits, and we accrue most of the costs.
It’s time to put users back in control of data they share with applications. To accomplish this, we’ll want to make two elements of the predominant consumer-oriented application model easier:
- It should be as easy for a user to create their own database as it is for them to create a document or send an email.
- It should be easy for an application to store data a user shares in a database that the user created and controls rather than in a database controlled by the application’s developer.
In this post, I’ll first describe how we got here and what the world looks like today. I’ll then propose a different model, where people maintain control over databases that applications use to store their data. Finally, I’ll close with some research directions that will ease the way for people to maintain control of their data.
How it works today: your data goes in, and never comes out
Historically, databases were designed to track things that were fully controlled by an enterprise. In Ted Codd’s seminal 1974 paper on relational databases, his example use case is that of a company tracking an inventory of parts required for various projects. In such a world, the user is an analyst or project manager updating and analyzing information that likely belongs to the company. The company wants a complete view of its inventory, and wants to control who, how, and when specific users access or change this information. Given these requirements, storing all of this company-controlled data in a company-controlled database is a reasonable choice.
In the late 1990s and early 2000s, with the rise of consumer-oriented database-backed applications, the question of who should control the data became more nuanced. As consumers started to send emails, create documents, take photos, and track their runs/meals/activities in applications, developers continued to use the centralized model of data storage. This meant placing all consumer-generated data in a single centralized database containing all of their users’ information:
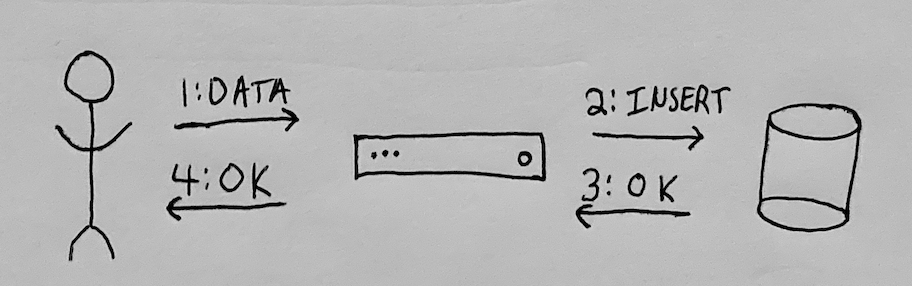
With time, consumers hit unpleasant surprises: applications limited what they could do with data they previously shared, and the data was used in ways consumers didn’t expect. Because data they generated was stored in someone else’s database, users felt a loss of control over their data. They couldn’t delete it, visualize it in a different way, or use it in another application. If the user wanted to get all of the data they previously shared with the application, there was no guarantee the application would allow that:
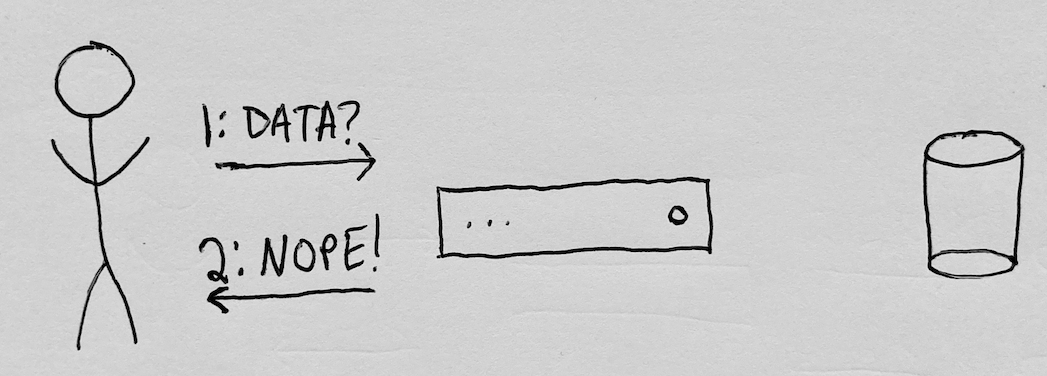
In this traditional centralized storage model, the owner of the database retains most of the power. They can restrict the user’s access to their own data. They can delete the data. They can sell the data to a third party. They might introduce a bug that allows other people to access the data. They might get compromised. Or they can avoid all of these mistakes just to be acquired, and have the new management change course.
That’s the state of the world in 2025: most everyone agrees that you should maintain some control over data you share with applications, but most everyone knows that our 1970’s-era architecture makes that challenging or impossible.
To be clear, some data should still be stored in centralized databases with restricted user access. Inventory is a great example: the business selling shoes needs to track how many of each shoe it has left, whereas the consumer only needs to know whether there are any shoes left to buy. A more nuanced example is click tracking and usage logs. Say a user consents to an application tracking their activity while editing a document (hopefully in exchange for something of value, like recommendations or an improved experience). The user’s click data is not the key focus of the user, who likely just wants to maintain control over their document, and it is most useful in aggregate across multiple users. If usage logs exist at all, they should probably be stored and analyzed in a centralized way that restricts user access.
It boils down to this: when users share information with an application (e.g., “I walked here” or “I ate that cake”), or when users rely on an application to create some work product (e.g., a document or email), they expect to maintain access to and control over the data and content they shared. By relying on an enterprise-centered architecture from the 1970s, users don’t get the control they expect. In the next section, we’ll see how to rearrange the traditional architecture to put users back in control.
How it should work: data we care about lives in databases we control
Let’s modify the architecture of the application above. What if it was easy for a user to create a personal database and authorize the application to access it? The user could maintain control of the database, and the application would gain credentials to the database for only as long as the user wished. An application might have access to many users’ databases, and would interact with each user’s database with credentials that the user authorized it to have. Here’s a user sharing the credentials to their database with an application:
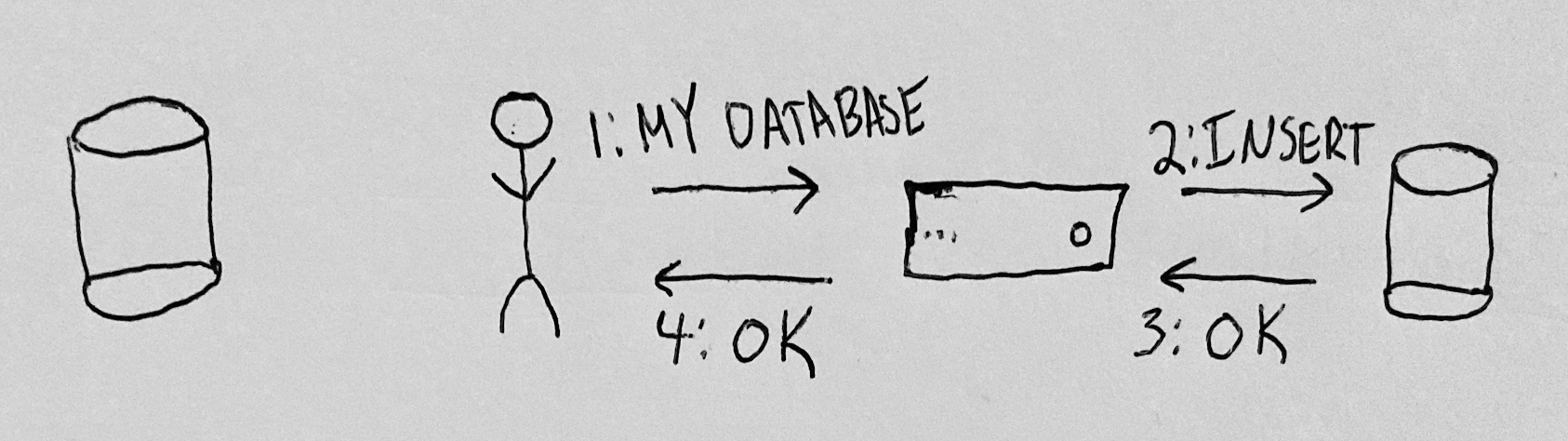
With those stored credentials, the application can service future requests from this user by querying the user’s database using the stored credentials:
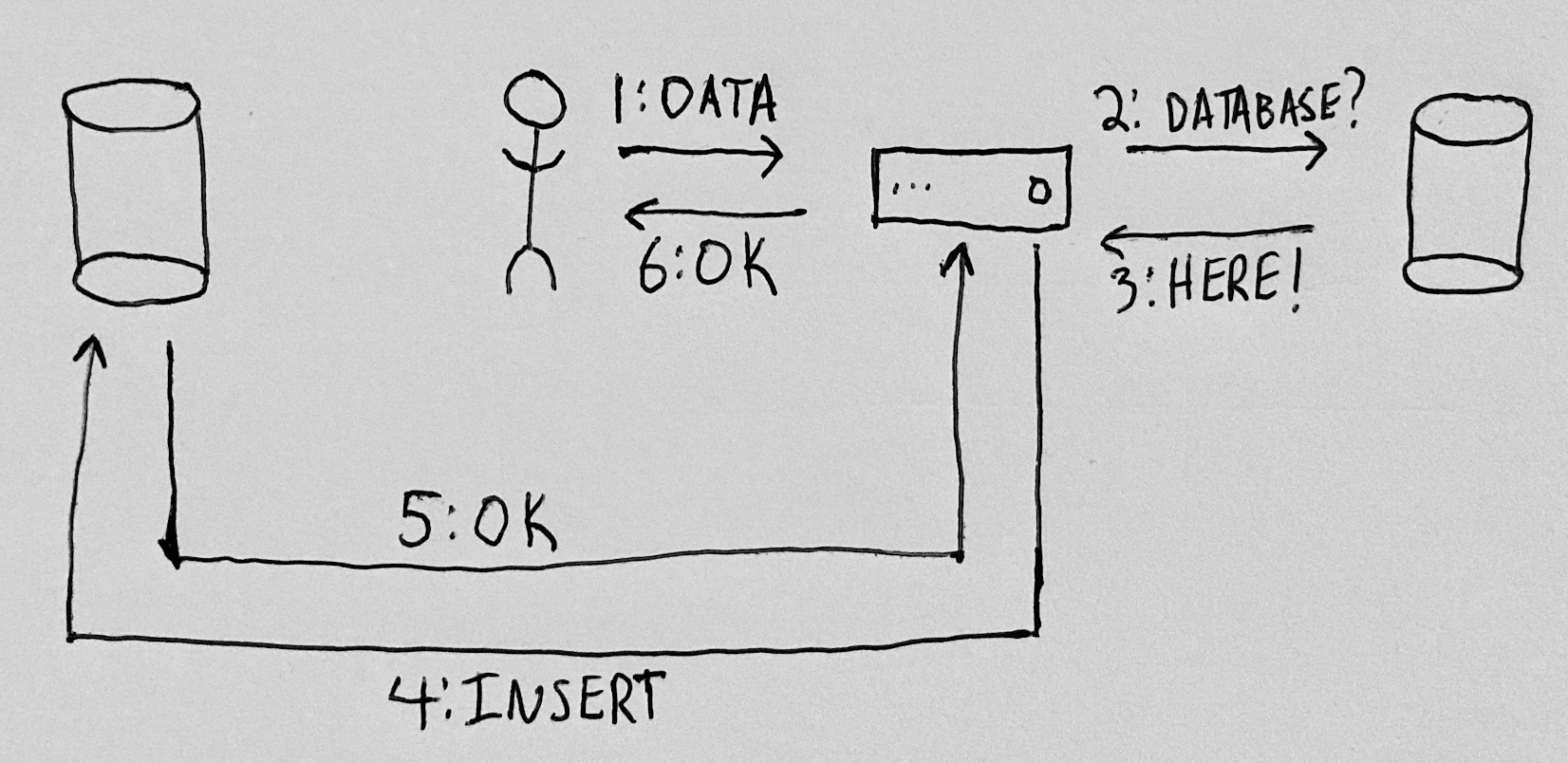
As long as the application continues to provide utility and the application owner keeps up their end of the bargain, the user can continue to authorize the application to access data in their personal database. Our user maintains control over their data, and can authorize multiple applications to interact with their database. They can modify their own data, or visualize it in ways any one application doesn’t allow. They can also decide it’s time to revoke access to some of those applications. Unlike in the traditional model, the user doesn’t have to rely on the application in order to access any of their previously shared data:
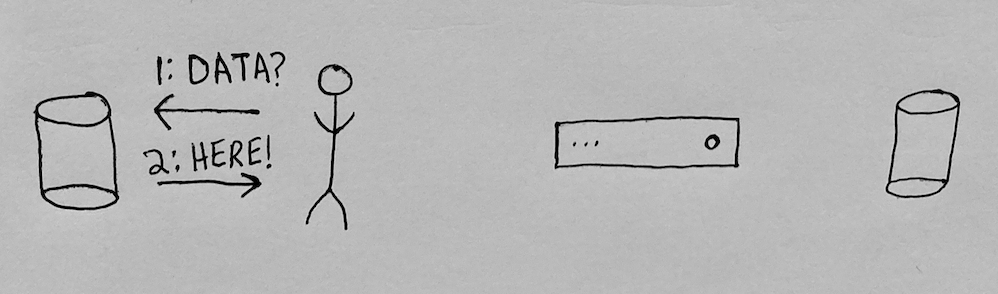
It’s worth pausing to acknowledge that this model, where everyone spins up databases for use in applications with ease, isn’t feasible today because it’s too hard for the average person to do, and because the developer support for building applications this way is largely non-existent. I’ll highlight a bunch of challenges in the next section, but these two challenges in particular need to be addressed above all others.
This model doesn’t solve all problems, and in particular, it’s not some infallible privacy solution. The user still shares data with a third-party application, and that application can do unsavory things with it like leaking data inadvertently or by design. A bug could still wipe out or corrupt a user’s database, and multiple applications might interact in unexpected or undesirable ways. But the ultimate source of truth for the application is a database controlled by the user, giving the user more choice, and application owners slightly more accountability if they want to keep a long-term relationship with the user.
Put simply: in the future, your data should live in your database, giving you more control over what happens to that data.
What would it take?
Any sane technologist should be skeptical of the proposal at this point. They will explain to you that databases are HARD! They’d ask if you really expect the average person to spin up a database? To back it up? To ensure it’s available? To authenticate it with applications? To monitor how their data is used and enforce their own policies?
Yes, I expect the average person to do all of these things, but not by technical mastery or sweating the details. The database community should provide users with technology that is designed and purpose-built to grant users sovereignty over their data. Here are a few of the hard problems the database community would have to solve:
- Easy database creation and maintenance. None of this works until it’s as easy to create and share databases as it is to create and share Google Docs. Easy database creation and maintenance is a big focus of my ayb project, which makes creating a reliable database that’s remotely accessible as easy as
ayb client create_database marcua/test.sqliteat the command line (with a web interface to come). Still, much more work in this space is required to allow any user to spin up a database with good availability and backups. - Authorization and usable security. Once a user creates their database, they have to share it with an application. How might we help developers and users do this easily and securely? The solution probably looks like a library that makes it possible to grant permission to the application through an OAuth 2.0-style flow, and then storing the credentials in the application’s database or in local storage/cookies on the client side. Client-side storage of credentials is particularly exciting, because it means applications might not need to store any state or details about the user at all!
- Audit logs, provenance, and policies. By sharing your database with an application, you’re opening yourself up to leaks and side-channel attacks. Still, what sort of logging, provenance, and monitoring can we offer users so that they can tell when and how their data is accessed, and by whom? Are there ways to specify policies that restrict how an application uses your data?
- Terms of data use. When you sign up for a service that stores your data today, you agree to Terms of Service (TOS) that dictate how you must act in order to keep using the service and accessing your own data. If you controlled your own database, you’d be able to bring your own set of terms to the relationship: in order to access your data, an application owner would have to agree to your Terms of Data Use (TODU). How could we make it easier for users to pick these terms, and what could we provide in terms of guarantees or monitoring that the application is sticking to the terms?
- Multi-user and collaboration. One beneficial side effect of the traditional application/database architecture is that, because all users are in one database, multi-user applications have a clear home for shared data. If everyone has their own database, it’s more challenging to build applications around shared data. How might we make it easier to federate collaborators’ databases?
- Migrations. It’s complicated enough to change the schema of a database or migrate the data in the database as your application changes. How can we ease the burden on application developers whose application now has to be able to speak with multiple databases, each of which are at different stages of being migrated?
- Performance, maybe. Databases are typically quite close to the servers hosting an application. If database servers and application servers are not as collocated, round trips between the two will incur additional latency. That said, modern applications generally rely on lots of third-party APIs, and so how bad is it really for an application to have to interact with a somewhat remote third-party database?
People, not rows
The many decades of success that relational databases have seen are in large part thanks to their power to provide an abstraction that addresses a wide variety of problems. That abstraction of tables and rows is technically powerful, but it also distracts us from what lies beneath: the rows of a database often contain people, activities, and secrets. Let’s keep building on the technical beauty that six decades of database research has provided, but let’s not forget who we’re building for: when databases contain people’s information, let’s help those people control their data.
Thank you to Timothy Danford, Lydia Gu, and Eugene Wu for reading early versions of this blog post and providing feedback that drastically changed it.